intel ultra125H 使用xpu的环境搭建
本文档介绍如何在搭载 Intel 酷睿 Ultra 5 125H(集成 Arc 核显)的设备上,使用 uv 管理 Python 环境并搭建 PyTorch XPU 深度学习开发工作流。
在 Intel 平台上,通常把 CPU、内置的 Arc GPU 以及 NPU 统称为 XPU。对于 PyTorch 框架,目前的策略是直接将核显(GPU)作为 xpu 设备来调用。
从 PyTorch 2.5 开始,Intel 的 GPU 支持已经原生合入官方版本。你可以按以下步骤在你的小新 Pro 16 上搭建环境并进行微小模型的训练。
🛠️ 第一步:前置驱动准备
为了让 PyTorch 能识别到你 Ultra 125H 的 Arc 核显,必须安装最新的 Intel 显卡驱动:
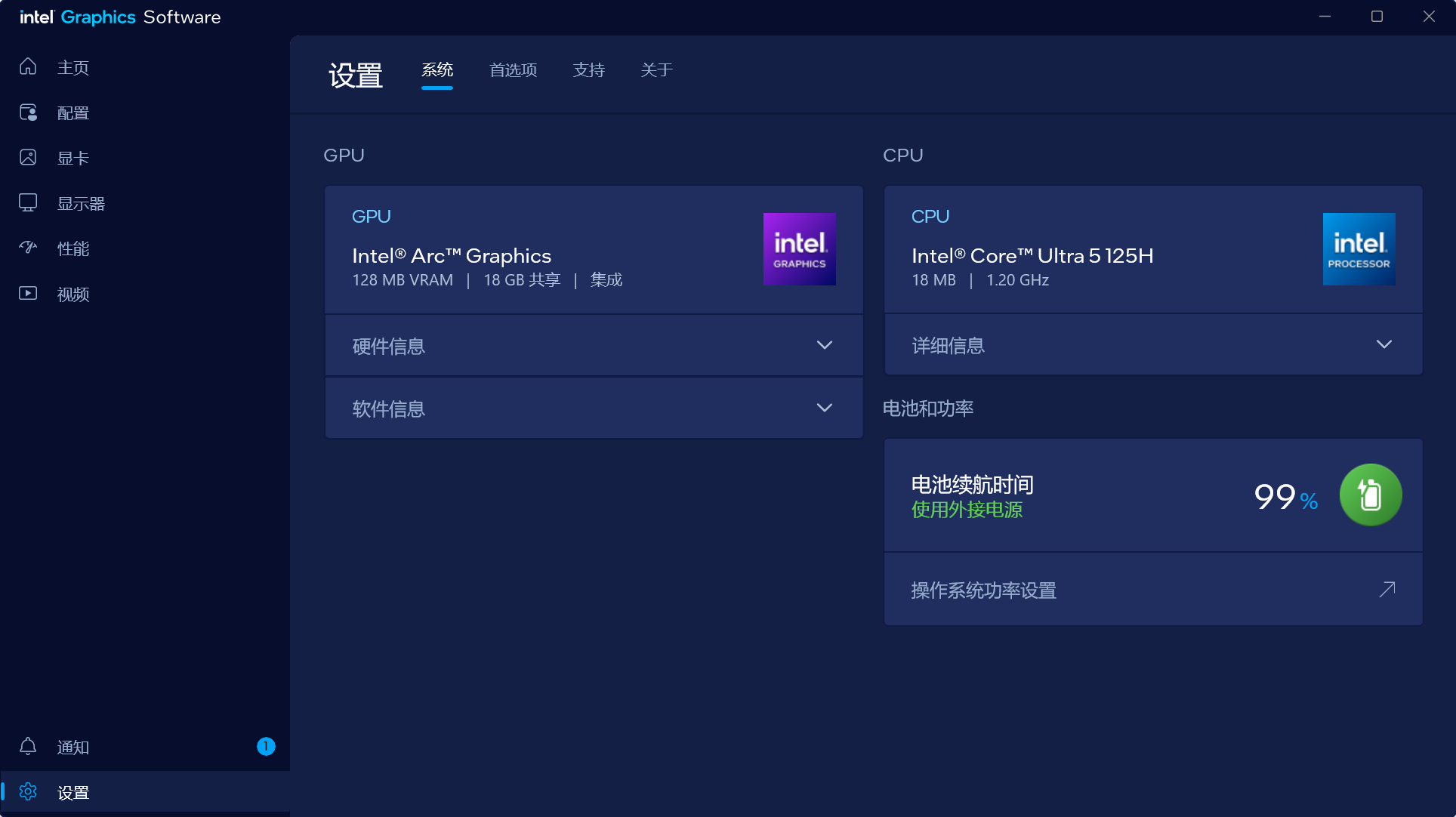
- 打开控制面板看一眼:在 Windows 开始菜单里搜一下 “Intel Graphics Software” 或者 “英特尔显卡软件”,看看能不能正常打开那个炫酷的蓝色调皮控制面板。
- 看一眼任务管理器“性能”页:
- 按
Ctrl + Shift + Esc打开任务管理器。 - 切换到 “性能”(Performance)标签页。
- 往下拉,看看左侧列表最下方有没有 GPU 0(通常名字叫
Intel(R) Arc(TM) Graphics)。
- 按
如果这两点都没问题,那你这台小新 Pro 16 的硬件环境就已经完全准备就绪了!
🐍 第二步:使用 uv 创建并配置 Python 环境
推荐使用 Python 3.11 或 3.12。我们利用 uv 快速拉起一个纯净的环境。
🚀 第一步:升级 uv 独立工具
在创建新项目之前,顺手把 uv 升到最新版,确保能用上最新的依赖解析算法:
1
uv self update
✨ 第二步:重新初始化并锁定 Python 3.12
现在我们重新建立项目。为了防止它默认又去抓你系统里的 Python 3.10,我们在初始化时就直接明确指定 Python 版本:
1
2
3
4
5
# 1. 初始化项目,并明确指定使用 python 3.12
uv init ai-labs --python 3.12
# 2. 进入新创建的文件夹
cd .\ai-labs\
📦 第三步:安装支持 XPU 的 PyTorch
现在文件夹里是最纯净的 uv 模板了。直接运行下面的命令,uv 会自动为你下载 Python 3.12 并配置好包含 Intel XPU 仓库的 PyTorch:
1
uv add torch torchvision torchaudio --index https://download.pytorch.org/whl/xpu
🛠️ 第四步:使用 uv add 安装 Jupyter 内核
在 uv 的项目管理模式下,安装 Jupyter 非常简单。不过,这里有一个非常优雅的 “现代前端/后端式” 做法。
由于你平时用 VS Code 作为主力 IDE,我们不需要在虚拟环境里安装庞大的 jupyter lab 或 jupyter notebook 网页端。我们只需要安装一个极简的内核(Kernel),然后直接在 VS Code 里写 Notebook 即可。
在终端中运行以下命令。这会将 ipykernel(Jupyter 的 Python 内核)作为开发依赖添加到你的项目中:
1
uv add ipykernel --dev
💡 为什么用 --dev? 因为 Jupyter 只是你用来实验、画图和写笔记的辅助工具,它不是你 AI 模型运行的业务代码。用 --dev 可以把开发工具和核心业务依赖(如 PyTorch)分开,保持 pyproject.toml 的条理清晰。
🚀 第五步:在 VS Code 中畅玩 Jupyter
依赖安装完成后,我们不需要在终端敲任何启动命令。
- 在 VS Code 中,在
ai-labs根目录下新建一个文件,命名为test_xpu.ipynb(注意后缀是.ipynb)。 - VS Code 会自动以漂亮的 Notebook 界面打开它。
- 关键步骤(选择内核):
- 看向 VS Code 窗口的右上角,会有一个 “Select Kernel”(选择内核)的按钮。
- 点击它,选择 Python Environments…。
- 找到并选择你当前项目下的虚拟环境(路径通常包含
.venv\Scripts\python.exe)。
📌 注意:如果提示需要安装 VS Code 的 Jupyter 扩展(Extension),直接点击允许安装即可。
🔍 如何验证大功告成?
等上面的依赖拉取完毕后,你可以用 VS Code 打开项目,看一下根目录下的 pyproject.toml。
如果 requires-python 显示的是 ">=3.12",且 dependencies 里有 torch,同时目录下有 .venv 文件夹,那就说明你已经亲手打造出了一个完美、纯净且现代化的 Intel XPU 深度学习开发环境!
🧪 第三步:在 Notebook 中验证 XPU
在新建的 test_xpu.ipynb 的第一个代码块(Cell)中,贴入以下代码并点击运行(快捷键 Shift + Enter):
1
2
3
4
5
6
7
8
9
import torch
print(f"PyTorch 版本: {torch.__version__}")
print(f"XPU 是否可用: {torch.xpu.is_available()}")
if torch.xpu.is_available():
print(f"成功抓取到核显: {torch.xpu.get_device_name(0)}")
else:
print("未检测到 XPU 设备,请检查驱动或 PyTorch 是否为 XPU 版本。")
现在,一个集成了 VS Code + uv + PyTorch XPU + Jupyter 的现代化深度学习工作流已经彻底打通了!
要不要我现在就为你提供一个经典的 MNIST 手写数字识别(AI 界的 Hello World)的 Notebook 代码块?你可以直接复制到这个 test_xpu.ipynb 里,亲眼看看你的酷睿 Ultra 125H 是如何一边画图一边训练微小模型的!
🧠 第四步:微小模型训练实战代码
太棒了!我们现在就来把这段经典的 MNIST 手写数字识别代码填进你的 test_xpu.ipynb 里。
这段代码专门为你优化过:
- 自动检测 XPU(Intel Arc 核显),并把模型和数据无缝搬运过去。
- 包含一个极简的可视化代码块,它会在训练前随机抽几张手写数字图片画出来,让你直观感受到 AI 是在认什么字。
- 使用轻量级的网络,你的酷睿 Ultra 125H 跑起来会非常轻松。
因为我们需要画图展示手写数字,需要用到 matplotlib 库。请在 VS Code 的终端里执行下面这行命令把它装上:
1
uv add matplotlib --dev
打开你的 test_xpu.ipynb,你可以新建几个代码块(Cell),或者直接把下面这一整段代码贴进一个大代码块里,然后点击运行(快捷键 Shift + Enter):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# ==========================================
# 1. 自动选择 XPU 设备 (Intel Arc 核显)
# ==========================================
device = torch.device("xpu" if torch.xpu.is_available() else "cpu")
print(f"当前使用的训练设备: {device}")
if torch.xpu.is_available():
print(f"已成功捕获显卡: {torch.xpu.get_device_name(0)}")
# ==========================================
# 2. 准备 MNIST 数据集 (手写数字)
# ==========================================
# 图像预处理:转为张量并标准化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
print("正在下载/加载 MNIST 数据集...")
# 自动下载训练集和测试集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)
# ==========================================
# 3. 画图展示:看看 AI 认的数据长啥样
# ==========================================
examples = enumerate(train_loader)
batch_idx, (example_data, example_targets) = next(examples)
plt.figure(figsize=(10, 4))
for i in range(5):
plt.subplot(1, 5, i + 1)
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title(f"Label: {example_targets[i]}")
plt.axis('off')
plt.show()
# ==========================================
# 4. 定义一个极简的卷积神经网络 (CNN)
# ==========================================
class TinyCNN(nn.Module):
def __init__(self):
super(TinyCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.relu = nn.ReLU()
self.max_pool = nn.MaxPool2d(2)
self.dropout = nn.Dropout2d()
def forward(self, x):
x = self.relu(self.max_pool(self.conv1(x)))
x = self.relu(self.max_pool(self.dropout(self.conv2(x))))
x = x.view(-1, 320)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return torch.log_softmax(x, dim=1)
# 将模型搬运到 XPU 上
model = TinyCNN().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
criterion = nn.NLLLoss()
# ==========================================
# 5. 开始微小模型训练循环
# ==========================================
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 核心:将数据搬运到 XPU 上
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 跑 2 个 Epoch 体验一下
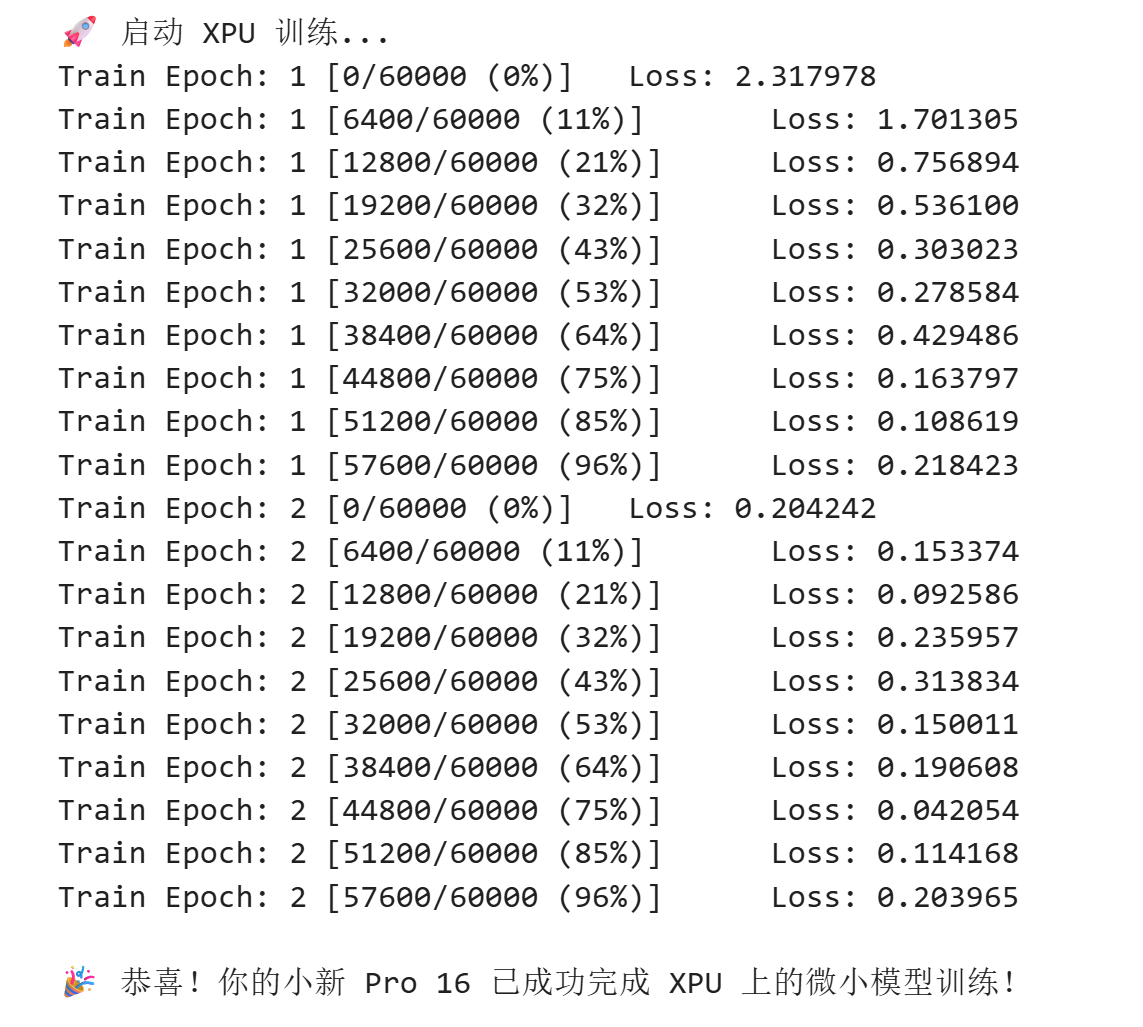
print("\n🚀 启动 XPU 训练...")
for epoch in range(1, 3):
train(epoch)
print("\n🎉 恭喜!你的小新 Pro 16 已成功完成 XPU 上的微小模型训练!")
🔍 你将看到什么?
- 控制台输出:会打印出
当前使用的训练设备: xpu以及你的显卡名称。 - 5张灰度图:Notebook 会直接渲染出 5 张黑底白字的手写数字,并带上它们原本的标签(Label)。
- 训练日志:你会看到 Loss(损失值)在一路下降,这代表 AI 正在飞速学习如何认字。

⚠️ 避坑与进阶指南
- 共享显存限制:Ultra 125H 是核显,它会共享你的系统内存(小新 16 Pro 2024 款通常是 16GB 或 32GB LPDDR5X)。如果训练稍微大一点的模型(比如轻量级 CV 模型),请注意盯一眼任务管理器,防止爆内存(OOM)。
- NPU 怎么用?:如果你想用 Ultra 处理器自带的独立 NPU,目前 PyTorch Eager 模式还不直接支持原生 NPU 训练。NPU 主要用于低功耗推理,通常需要借助 OpenVINO 工具套件将模型导出后运行。
xpu和英伟达的gpu3050ti,哪儿个训练模型快和好?
这是一个非常硬核且直击痛点的问题!既然你提到了 NVIDIA RTX 3050 Ti,那咱们就拿它和你的 酷睿 Ultra 5 125H 的 Arc 核显(XPU) 来做一次深度的心智 PK。
直接给结论:RTX 3050 Ti 在绝大多数真实训练场景下依然更“快”也更“好”;但你的 XPU 在“显存容量”这个维度上,完成了对 3050 Ti 的降维打击。
为了让你彻底搞懂,我们可以从以下几个核心维度来进行对比:
🏎️ 1. 速度 PK:谁训练得更快?
🥇 胜者:NVIDIA RTX 3050 Ti(速度)
- 生态与指令集(绝对优势):NVIDIA 经营了十几年的 CUDA 生态太强大了。深度学习框架(PyTorch、TensorFlow)的底层算子几乎都是为了 CUDA 极致优化的。3050 Ti 拥有独立的 Tensor Core(张量核心),在处理矩阵乘法(AI 的底层逻辑)时效率极高。
- 硬件架构:3050 Ti 是一块独立显卡,拥有独立的显存带宽和更高的功耗释放(通常在 $35W \sim 80W$ 之间)。而你的 Ultra 125H 核显(XPU)虽然底子不错,但它需要和 CPU 共享功耗(受限于小新 Pro 16 的轻薄机身散热,整机功耗是有上限的),在密集的矩阵计算中,绝对算力弱于 3050 Ti。
💾 2. 模型规模 PK:谁能训练更大的模型?
🥇 胜者:Intel XPU(Arc 核显)
这是你的小新 Pro 16 最扬眉吐气的一项:
- RTX 3050 Ti 的致命死穴:它只有 4GB 的独立显存。在深度学习里,4GB 显存是极其局促的,你稍微把 Batch Size(批次大小)调大一点,或者塞一个层数稍多的模型,立刻就会报经典的
OOM(Out of Memory,显存溢出) 错误。 - XPU 的降维打击:从你刚才发给我的控制面板截图来看,你的 Arc 核显拥有 18GB 的共享显存。这意味着只要你的电脑内存够大,你就可以把 Batch Size 调得很大,甚至能强行塞进去一些 3050 Ti 连碰都不敢碰的中小型模型(比如一些轻量级的大语言模型、LoRA 微调等)。
🛠️ 3. “好用”程度 PK:谁的生态更省心?
🥇 胜者:NVIDIA RTX 3050 Ti(易用性)
- 英伟达 (CUDA):基本属于“有手就行”。网上的开源 AI 项目、GitHub 代码,99% 默认都是写着
device = 'cuda'。你下载下来直接就能跑,不需要改任何代码,各种奇奇怪怪的第三方库(如flash-attn等加速库)也全部默认支持。 - 英特尔 (XPU):属于“未来可期”。正如你刚才体验到的,虽然 PyTorch 原生支持了 XPU,但我们需要去折腾专门的下载源、环境变量、甚至要提防
uv偷偷把包换成 CPU 版。遇到一些稍微复杂的开源模型,你可能需要手动把代码里的.cuda()改成.xpu()才能跑。
📊 总结与建议
我把它们两者的特点整理成了一个直观的对比表:
| 维度 | NVIDIA RTX 3050 Ti (4GB) | Intel Arc GPU / XPU (18GB 共享) |
|---|---|---|
| 小模型训练速度 | 🚀 极快(CUDA + Tensor Core 降维打击) | 🐢 较慢(受限于核显带宽与功耗) |
| 能吃下的模型大小 | ❌ 极小(4GB 显存是瓶颈,极易 OOM) | 🔋 较大(可利用高达 18GB 的共享内存) |
| 代码兼容性 | 💯 完美(所有 AI 项目默认支持) | ⚠️ 一般(部分项目需要手动适配改代码) |
| 发热与续航 | 🔥 发热大,风扇狂飙 | 🍃 发热相对小,功耗控制更好 |
💡 最终建议
- 如果你只是学习、跑跑微小模型、做做数据分析:你的小新 16 Pro 的 XPU 完全够用,而且 18GB 的大显存能让你非常任性地调大 Batch Size。
- 如果是为了打比赛、跑复杂的 CV(计算机视觉)或者 NLP(自然语言)大模型:一台拥有大显存(至少 12GB+)的英伟达显卡电脑依然是不可替代的生产力工具。
既然现在你的 XPU 显存很大,要不要试着把刚才 MNIST 的 batch_size=64 强行改成 batch_size=1024 甚至更大,看看你的 Ultra 125H 会不会报错?